 python3基础
python3基础
# 一、python编程基础
| 类型 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 编译型语言 | 通过专门的编译器,将所有源代码一次性转换成特定平台(Windows、Linux、macOS等)的机器码(以可执行文件的形式存在)。 | 编译一次后,脱离了编译器也能运行,并且运行效率高。 | 可移植性差,不够灵活。 |
| 解释型语言 | 通过专门的解释器,根据需要可以将部分或全部源代码转换成特定平台(Windos、Linux、macOS等)的机器码。 | 跨平台性好,通过不同的解释器,将相同的源代码解释成不同平台下的机器码。 | 一边执行一边转换,效率较低。 |
- Python 简单易用,学习成本低,看起来非常优雅干净;
- Python 标准库和第三库众多,功能强大,既可以开发小工具,也可以开发企业级应用;
- Python 站在了人工智能和大数据的风口上,站在风口上,猪都能飞起来。
• Python官方文档: https://www.python.org/doc • iPython:升级版的python解释器 • PyCharm:一款功能强大的Python集成开发环境 • Sublime:代码编辑器 • Jupyter notebook:在网页中编写和运行代码 • Pip: Python模块安装工具
# 应用
- Web应用开发: Django、Flask、Tornado、Web2py
- 自动化运维:pywin32 、IronPython
- 人工智能领域: Google 的 TransorFlow(神经网络框架)、FaceBook 的 PyTorch(神经网络框架)以及开源社区的 Karas 神经网络库
- 网路爬虫: urllib、Selenium 、 BeautifulSoup 、 Scrapy
- 科学计算:NumPy、SciPy、Matplotlib、pandas
- 游戏开发: Python 可以直接调用 Open GL 实现 3D 绘制,这是高性能游戏引擎的技术基础。事实上,有很多 Python 语言实现的游戏引擎,例如 Pygame、Pyglet 以及 Cocos 2d 等
# 二、安装python环境
# python下载
Download Python | Python.org (opens new window)
python -V
pip list #显示安装了哪些库
python -m pip install --upgrade pip # 升级pip
2
3
# python centos7下升级安装
centos7默认安装的是python2.7,在Linux系统下,路径/usr/local相当于C:/Progrem Files/,通常安装软件时便安装到此目录下。
sudo yum install -y bzip2*
sudo yum -y install bzip2 bzip2-devel ncurses openssl openssl-devel openssl-static xz lzma xz-devel sqlite sqlite-devel gdbm gdbm-devel tk tk-devel libffi-devel
wget http://npm.taobao.org/mirrors/python/3.11.2/Python-3.11.2.tgz
tar -zxvf Python-3.11.2.tgz
2
3
4
5
6
cd Python-3.11.2
# 生成makefile文件 配置安装目录
./configure --prefix=/usr/local/python3
make && make install
2
3
4
不指定prefix,可执行文件默认放在/usr/local/bin,库文件默认放在/usr/local/lib,配置文件默认放在/usr/local/etc,其它的资源文件放在/usr/local/share
# 方式一:
直接创建python3软链,利用命令 python3 调用新版本python,与自带python不冲突, ln -s a b # 建立软连接,b指向a, python3 -V, pip3 -V
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
2
方式二:
备份旧python与pip
mv /usr/bin/python /usr/bin/python2_old
mv /usr/bin/pip /usr/bin/pip2_old
2
修改软链接
ln -s /usr/local/python3/bin/python3 /usr/bin/python
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip
2
参考:
CentOS7升级Python版本 (opens new window)
# pycharm
Thank you for downloading PyCharm! (jetbrains.com) (opens new window)
PyCharm 2022.2.2 激活破解码_安装教程 (持续更新~) - 异常教程 (exception.site) (opens new window)
-javaagent:d:/chrome/ja-netfilter/ja-netfilter.jar
--add-opens=java.base/jdk.internal.org.objectweb.asm=ALL-UNNAMED
--add-opens=java.base/jdk.internal.org.objectweb.asm.tree=ALL-UNNAMED
2
3
VAE9B0CRYZ-eyJsaWNlbnNlSWQiOiJWQUU5QjBDUllaIiwibGljZW5zZWVOYW1lIjoiZnV6emVzIGFsbHkiLCJhc3NpZ25lZU5hbWUiOiIiLCJhc3NpZ25lZUVtYWlsIjoiIiwibGljZW5zZVJlc3RyaWN0aW9uIjoiIiwiY2hlY2tDb25jdXJyZW50VXNlIjpmYWxzZSwicHJvZHVjdHMiOlt7ImNvZGUiOiJQU0kiLCJmYWxsYmFja0RhdGUiOiIyMDIzLTA3LTAxIiwicGFpZFVwVG8iOiIyMDIzLTA3LTAxIiwiZXh0ZW5kZWQiOnRydWV9LHsiY29kZSI6IlBDIiwiZmFsbGJhY2tEYXRlIjoiMjAyMy0wNy0wMSIsInBhaWRVcFRvIjoiMjAyMy0wNy0wMSIsImV4dGVuZGVkIjpmYWxzZX0seyJjb2RlIjoiUFBDIiwiZmFsbGJhY2tEYXRlIjoiMjAyMy0wNy0wMSIsInBhaWRVcFRvIjoiMjAyMy0wNy0wMSIsImV4dGVuZGVkIjp0cnVlfSx7ImNvZGUiOiJQQ1dNUCIsImZhbGxiYWNrRGF0ZSI6IjIwMjMtMDctMDEiLCJwYWlkVXBUbyI6IjIwMjMtMDctMDEiLCJleHRlbmRlZCI6dHJ1ZX0seyJjb2RlIjoiUFdTIiwiZmFsbGJhY2tEYXRlIjoiMjAyMy0wNy0wMSIsInBhaWRVcFRvIjoiMjAyMy0wNy0wMSIsImV4dGVuZGVkIjp0cnVlfV0sIm1ldGFkYXRhIjoiMDEyMDIyMDcwMVBTQU4wMDAwMDUiLCJoYXNoIjoiVFJJQUw6MTMxNzYyODYxMCIsImdyYWNlUGVyaW9kRGF5cyI6NywiYXV0b1Byb2xvbmdhdGVkIjpmYWxzZSwiaXNBdXRvUHJvbG9uZ2F0ZWQiOmZhbHNlfQ==-YxAJSVk5XIZkkI6vH33zgb/hRmCdqia89zpsVHp2x52PY0XgOOiAlcR3/BVhm0qRYLBYBBHMpPcz0+ZWr2diKy0QexfbtVIVsCRkVaRgl67Tbw9MKb5jVNqpqth2yEoW/gmm2bZC5RS0qiGcPQpjD7AdRo66P78Vb2TrJ5hz055polMwR0hMxm9ECDedLnqKQXyzmcjkucStFNYYHbF0Gnn0I/xrxnVoIDeHMdlsRiBXYPb6TGIVgOIh8ynuGwvP/svLVPCI1dYPYF1V3ndDbOOQskOJaC+7K1/80xVEb3TT7Orb7PJJDX1AiIjg0gsSctPulz3r1xLHIZNcZJcV0A==-MIIETDCCAjSgAwIBAgIBDTANBgkqhkiG9w0BAQsFADAYMRYwFAYDVQQDDA1KZXRQcm9maWxlIENBMB4XDTIwMTAxOTA5MDU1M1oXDTIyMTAyMTA5MDU1M1owHzEdMBsGA1UEAwwUcHJvZDJ5LWZyb20tMjAyMDEwMTkwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCUlaUFc1wf+CfY9wzFWEL2euKQ5nswqb57V8QZG7d7RoR6rwYUIXseTOAFq210oMEe++LCjzKDuqwDfsyhgDNTgZBPAaC4vUU2oy+XR+Fq8nBixWIsH668HeOnRK6RRhsr0rJzRB95aZ3EAPzBuQ2qPaNGm17pAX0Rd6MPRgjp75IWwI9eA6aMEdPQEVN7uyOtM5zSsjoj79Lbu1fjShOnQZuJcsV8tqnayeFkNzv2LTOlofU/Tbx502Ro073gGjoeRzNvrynAP03pL486P3KCAyiNPhDs2z8/COMrxRlZW5mfzo0xsK0dQGNH3UoG/9RVwHG4eS8LFpMTR9oetHZBAgMBAAGjgZkwgZYwCQYDVR0TBAIwADAdBgNVHQ4EFgQUJNoRIpb1hUHAk0foMSNM9MCEAv8wSAYDVR0jBEEwP4AUo562SGdCEjZBvW3gubSgUouX8bOhHKQaMBgxFjAUBgNVBAMMDUpldFByb2ZpbGUgQ0GCCQDSbLGDsoN54TATBgNVHSUEDDAKBggrBgEFBQcDATALBgNVHQ8EBAMCBaAwDQYJKoZIhvcNAQELBQADggIBABqRoNGxAQct9dQUFK8xqhiZaYPd30TlmCmSAaGJ0eBpvkVeqA2jGYhAQRqFiAlFC63JKvWvRZO1iRuWCEfUMkdqQ9VQPXziE/BlsOIgrL6RlJfuFcEZ8TK3syIfIGQZNCxYhLLUuet2HE6LJYPQ5c0jH4kDooRpcVZ4rBxNwddpctUO2te9UU5/FjhioZQsPvd92qOTsV+8Cyl2fvNhNKD1Uu9ff5AkVIQn4JU23ozdB/R5oUlebwaTE6WZNBs+TA/qPj+5/we9NH71WRB0hqUoLI2AKKyiPw++FtN4Su1vsdDlrAzDj9ILjpjJKA1ImuVcG329/WTYIKysZ1CWK3zATg9BeCUPAV1pQy8ToXOq+RSYen6winZ2OO93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXugOoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5zfhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZOEmH0nOnH/0onD
pycharm如何配置python环境-Python学习网 (opens new window)
插件: Chinese Language Pack、translation (翻译)、Eclipse keymap (快捷键)
# 安装python库
# 修改pip源
步骤一、点击此电脑,在最上面的的文件夹窗口输入 :%APPDATA%
步骤二、按回车跳转到以下目录,新建 pip 文件夹
步骤三、创建 pip.ini 文件
步骤四、打开文件夹,输入以下内容,关闭即可(注意:源镜像可替换)
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
2
3
4
临时修改
pip install requests -i http://mirrors.aliyun.com/pypi/simple/
pip换源 -pip更换国内镜像源_Saggitarxm的博客-CSDN博客_python更换pip源 (opens new window)
# 三、Python数据格式与语法
# 1、输入input
name = input("请输入名称:");
print("名称为:"+name, type(name));
2
input(<tips>)返回值的类型为str, 如果要进行计算的话,需要进行转换 int()、float()、 eval()、 exec()等内建函数操作
(1)float(<数字>)用于将字符串数字或数值型数字转为浮点数,可用于计算。
(2)int(<数字>)用于将字符串数字或数值型数字转为整数,可用于计算。
(3)type(<object>)用于判断对象的类型,返回结果可为str、int、float、list等。
# 2、注释
# :单行注释
""" """或者 ''' ''' :多行注释
"""
这是多行注释
"""
# 这是一行注释
# Author: shollin
print("我是Python!");
2
3
4
5
6
7
# 3、运算符
# 算术运算符
算术运算符有加(+)、减(-)、乘(*)、除(/)、取模(%)、幂(**)、向下取整数(//)。
(+):不仅可以计算数字相加,还可以字符串连接
(*): 还可以表示字符串重复次数
除(/)、取模(%)、取整数(//)返回的类型为float
math.ceil() math.floor(); 向下取整,相像成楼梯,取天花板和地板
int() 只取整数部分
round() 正好.5的时候找离.5最近的偶数,四舍六入五取偶 如round(2.5)为2 rount(0.5)为0
# 比较运算符
比较运算符有等于(==)、不等于(!=)、大于(>)、小于(<)、大于等于(>=)、小于等于(<=)。
# 逻辑运算符
and(与)、or(或)、not(非)三种逻辑运算符
# 成员运算符(in)
如果在指定的对象中找到指定的值,则返回 True,否则返回 False。也可以使用 not in来测试对象中没有指定的值
- 只对字符串起作用
| 操作符 | 描述 | 示例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回False | computer = ["主机","显示器","鼠标","键盘"] ("主机" in computer) 结果True ("音响" in computer) 结果False |
| not in | 如果在指定的序列中没有找到值 返回True,否则返回False | print("主机" not in computer) 结果False print("音响" not in computer) 结果True |
# 身份操作符is
身份操作符:判断两个对象是否相等
| 操作符 | 描述 |
|---|---|
| is | 判断两个标识符是否引用一个对象,比较内存地址 |
| is not | 判断两个标识符是否引用不同对象 |
- 当两个对象用
==来比较时,会调用__eq__方法,若没有eq方法,则调用object的eq, 最终转为is比较
# 4、对象
对象内存地址: id()函数
对象类型: type() 函数
# 5、字面量

# 6、字符串
a.查找_替换_统计
find() 掌握 注意: 找不到子串时,返回-1
rfind() 了解
index() 了解 注意: 找不到子串时,程序会崩溃,产生一条异常信息,导致程序无法执行
rindex() 了解
replace() 掌握 默认全部替换
count() 掌握
b. 分割_连接
split() 掌握 输出的是列表,需要注意有分隔符,且每个都会生效
splitlines() 理解 注意只识别换行为分隔符
partition() 了解 只会分割成三部分,且输出一个元组
rpartition() 了解
join() 掌握 加入字符进行连接列表中的每个元素
c. 判断
startswith() 判断是否以指定字符串开头 (掌握)
endswith() 判断是否以指定字符串结束 (掌握)
isupper() 判断是不是大写字符 (理解)
islower() 判断是不是小写字符 (理解)
isdigit() 判断是不是数字字符 (理解)
isalpha() 判断是不是字母 (理解)
isalnum() 判断是不是字母或数字字符 (理解)
isspace() 判断是不是空白字符,包含空格,换行符\n,制表符\t (理解)注意''空字符串不是空白字符
d. 转换 (理解)
upper() 转换成大写
lower() 转换成小写
title() 将每个单词首字符转换大写
capitalize() 将第一个单词的首字符转换成大写
e. 对齐 (理解)
center() 按给定宽度居中显示
rjust() 右对齐
ljust() 左对齐
f. 去除空白(理解)
strip() 去除两端空白
lstrip() 去除左侧空白
rstrip() 去除右侧空白
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 1、切片提取

# 提取单个字符
str[位置],既可以从开头计算,也可以从结尾计算。开头从0开始,结尾为-1
# 提取多个字符
str [开始位置:结束位置:步长值]
- 包含开始位置,不包含结束位置,步长值可以为负值,负值时表示从后往前提取
- 开始位置可以省略,省略表示从0开始
- 结束位置也可以省略,省略表示到结尾,包含结尾字符
- 开始位置和结束位置都省略,表示全部输出
s="Excel我很忙";
print("第一个字符:%s, 最后一个:%s" % (s[0],s[-1]));
print("第二个到第五个字符:%s" % (s[1:6]));
print(s[:5]); #Excel
print(s[5:]); #我很忙
print(s[:]); #Excel我很忙
print(s[-3:]); #我很忙
print(s[::-1]); #忙很我lecxE
2
3
4
5
6
7
8
9
10
# 2、字符串长度(个数)统计
# len
len 方法返回对象(字符、列表、元组等)长度或项目个数。比如代码:print(len('Excel')),最后返回值为 5
# count
count 方法用于统计字符串里指定字符串出现的次数。可选参数为在字符串搜索的开始与结束位置,语法格式为:str.count(sub, start= 0,end=len(string))。
- str 被搜索的父字符串; sub 搜索的子字符串; start 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为 0。end 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
# 3、字符串的查找
# index
index() 方法用于从字符串中找出某个对象第一个匹配项的索引位置,如果查找的字符串不存在会报一个异常。
str.index(sub[,start=0[,end=len(str)]])
- str 父字符串; sub 指定检索的子字符串; start 可选参数,开始索引,默认为 0。(可单独指定); end 可选参数,结束索引,默认为字符串的长度。(不能单独指定)
# find
find() 方法从字符串中找出某个子字符串第一个匹配项的索引位置,该方法与 index 方法一样,只不过如果子字符串不在字符串中不会报异常,而是返回-1。
# 4、字符串的替换replace
replace() 方法用于把字符串中指定的旧子字符串替换成指定的新子字符串,如果指定count 可选参数则替换指定的次数,默认全部替换。
str.replace(old,new,[,count=str.count(old)])
- old :指定的旧子字符串; new指定的新子字符串; count 可选参数,替换的次数,默认为指定的旧子字符串在字符串中出现的总次数。
# 5、字符串的拆分与合并
# split
split 方法拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list),语法结构:str.split(str="",num=string.count(str))
- str 表示为分隔符,默认为空格,但是不能为空('')。若字符串中没有分隔符,则把整个字符串作为列表的一个元素。num :表示分割次数。如果存在参数 num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量。
# join
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
语法结构:str.join(sequence)
str 分隔符。可以为空; sequence要连接的元素序列、字符串、元组、字典
# 6、字符串格式化输出
格式化字符串分为百分号(%)方法和 format 方法
1、+
注意: 数字不能直接和字符串进行拼接,需用str()进行转换
2、f格式化
3、特殊字符
| \t | tab键缩进 |
|---|---|
| \n | 换行 |
| \r | 回车 |
- 如果要输出特殊字符,可以用
r""或者 转义字符\
name="张三";
age = 25;
print("我的名字:" + name);
# print("我的名字:"+ name + ",年龄:" + age); # can only concatenate str (not "int") to str
print("我的名字:"+ name + " \t年龄:" + str(age));
print(r'我是谁!\n 我在哪儿!') # 输出特殊字符
print(f"我的名字:{name},年龄:{age}");
2
3
4
5
6
7
8
9
10
百分号方式格式:%[(name)][flags][width].[precision]typecode,接下说明一下这些参数。
[(name)] 可选,用于选择指定的 key
[flags] 可选,可供选择的值有:
+,右对齐,正数前加正号,负数前加负号。
-,左对齐,正数前无符号,负数前加负号。
空格,右对齐,正数前加空格,负数前加负号。
0,右对齐,正数前无符号,负数前加负号,用 0 填充空白处。Python 从零基础开始处理 Excel 作者:曾贤志
[width] 可选,占有宽度。
.[precision] 可选,小数点后保留的位数,会四舍五入。
typecode 必选
s,获取传入的对象__str__方法的返回值,并将其格式化到指定位置
d,将整数,浮点数转化为十进制表示,并将其格式化到指定位置
f,将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6 位)
num = 123.2343
print("%+.3f"% num); # 输出:+123.234
2
# 7、字符串前加rbuf前缀
r为raw,表示非转义的原始字符串,\n \b \r ... 等转义符号,就不进行转义了
b为bytes, 表示该字符串是bytes类型
u 表示unicode字符串,对于任何的字符串,代表是对字符串进行unicode编码
f 为format, 表示格式化操作,相比于format()更方便使用
参考: Python中字符串前“b”,“r”,“u”,“f”的作用 (opens new window)
# 7、数字
Python 中的数字有三种类型:整数 (int)、浮点数(float 小数)、复数 (complex) 3 种。有时需要对数据进行转换,可以使用对象的函数,转为整数使用 int() 函数,转为小数使用 float() 函数,转为复数使用 complex() 函数。
数字也可以与算术运算术符结合进行算术运算。
# 8、布尔
True:
False:
# 9、列表
增:
append()
extend()
insert()
修:
下标修改
查:
index()
count()
in (掌握)
not in
删:
pop()
remove()
clear() 清空但列表存在
del 全没了
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
列表的格式为[元素 1,元素 2,元素 3……]
列表中元素的数据类型,可以是任意数据类型,但要注意正确的表达方式。
列表中可以再嵌套列表
列表的循环遍历
for in空列表的表示方法: []
# 1、列表切片
同字符串的切片,Python 中符合序列的有序序列都支持切片,例如列表,字符串,元组。切片格式为:[start:end:step] 包含start,不包含end
# 2、列表的增加、删除、修改
# 添加:append和insert
# 删除:pop、remove、clear方法和del语句
# 3、列表操作符
+ * in
# 4、列表推导式
列表推导式是 Python 基础,好用,而又非常重要的功能,也是最受欢迎的 Python 特性之一,可以说掌握它是成为合格 Python 程序员的基本标准。本质上可以把列表推导式理解成一种集合了转换和筛选功能的函数,通过这个函数把一个列表转换成另一个列表。注意是另一个新列表,原列表保持不变。
# 1.列表推导
[表达式 for 变量 in 列表]
# 2.列表嵌套推导
[表达式 for 变量 1 in 列表 1 for 变量 2 in 列表 2]
# 3.条件列表推导
[表达式 for 变量 1 in 列表 if 条件]
# 5、列表转换
list(),Python 的 list 函数可以将其他数据类型转换为列表类型,并返回转换后的列表。当参数为空时,list 函数可以创建一个空列表。
reverse(),Python 列表 reverse() 方法对列表中的元素进行反向排序,不产生新对象
copy(),copy 方法是用于复制列表元素的,会产生新对象
zip(): zip 函数是可以接收多个可迭代对象,然后把每个可迭代对象中的第i个元素组合在一起,形成一个新的迭代器,类型为元组
zip() 与 * 运算符相结合可以用来拆解一个列表
提取迭代器数据的方法,next(),list(),for in
# 6、列表统计
len 计数、max 最大值、min 最小值、sum 求和
Index
Python 列表 index() 方法用于从列表中找出某个对象第一个匹配项的索引位置,如果这个对象不在列表中会报一个异常。
index() 方法语法:
L.index(obj[,start=0[,stop=len(L)]])- obj 查找的对象; start 可选参数,开始索引,默认为 0。(可单独指定); stop 可选参数,结束索引,默认为列表的长度。(不能单独指定)
count
Python 列表 count() 方法用于统计某个元素在列表中出现的次数。
count() 方法语法:
L.count(obj)- obj 列表中统计的对象。
# 统计元素出现的次数
方式一: 利用字典
a = [2, 2, 1, 3, 1, 2]
dict = {}
for key in a:
dict[key] = dict.get(key, 0) + 1
print dict
2
3
4
5
方式二:
使用函数Counter,可以迅速获取list中每个元素出现的次数
from collections import Counter
a = [2, 2, 1, 3, 1, 2]
result = Counter(a)
print result
2
3
4
方式三: 利用count
list1=[1,5,5,2,2,2,1,3]
def all_list(list1):
result = {}
for i in set(list1):
result[i]=list1.count(i)
return result
print(all_list(list1))
2
3
4
5
6
7
8
参考: https://blog.csdn.net/weixin_42121905/article/details/113971303
# 10、元组(Tuple)
元组被称为只读列表,数据可被查询,但不能被修改,元组写在小括号里面()元素之间用逗号隔开。对于一些不想被修改的数据,可以用元组来保护。
元组与列表的互转: tuple、list
t = (1,2,3);
l = list(t); # 转成列表
l+=["张三"];
print(tuple(l)); #转成元组
t1=('销售部-张三','财务部-李诗','销售部-周立新','IT 部-曾贤志','销售部-梁芬')
t2=(t for t in t1 if t[:3]=='销售部')
print(tuple(t2))
2
3
4
5
6
7
8
# 11、字典(dict)
Python 字典(dict)是一种无序的、可变的序列,且可存储任意类型对象,如字符串、数字、元组等其他容器模型,字典由键和对应值成对组成。字典也被称作关联数组或哈希表。基本语法如下:d = {key1 : value1, key2 : value2 }
字典的每个键值 key=>value 对用冒号(:)分割,每个键值对之间用逗号(,)分割,整个字典包括在花括号({})中。
如果要创建空字典,有如下两种方法:
方法 1:空字典创建,使用
{}或者dict()方法 2:使用
dict
| 主要特征 | 解释 |
|---|---|
| 通过键而不是通过索引来读取元素 | 字典类型有时也称为关联数组或者散列表(hash)。它是通过键将一系列的值联系起来的,这样就可以通过键从字典中获取指定项,但不能通过索引来获取。 |
| 字典是任意数据类型的无序集合 | 和列表、元组不同,通常会将索引值 0 对应的元素称为第一个元素,而字典中的元素是无序的。 |
| 字典是可变的,并且可以任意嵌套 | 字典可以在原处增长或者缩短(无需生成一个副本),并且它支持任意深度的嵌套,即字典存储的值也可以是列表或其它的字典。 |
| 字典中的键必须唯一 | 字典中,不支持同一个键出现多次,否则只会保留最后一个键值对。 |
| 字典中的键必须不可变 | 字典中每个键值对的键是不可变的,只能使用数字、字符串或者元组,不能使用列表。 |
# 1、键特点
键必须具有唯一性
键必须不可变: 列表不能做键,因为列表不能哈希 unhashable
# 2、字典的增删改

# 删除字典
d.clear()
pop(key): 删除字典给定键 key 所对应的值,返回值为被删除的值
popitem(): 随机返回并删除字典中的一对键和值
del d1 del 全局方法(能删单一的元素也能清空字典,清空只需一项操作)
# 字典键名的修改
d[newKey] = d.pop[oldKey] : 删除旧的key,将值赋给新的key
# 字典的连接update
d1.update(d2)
# 字典的查询
使用in dict.keys()判断指定的键名是否在字典中存在
# 3、字典转换
dict():
dict.fromKeys() : 第一个参数是一个列表或者元组,里边的值为 key,第二个参数是所有 key 的 value 值。
# 4、字典的循环
默认循环读取键名
d.keys(): 返回字典的所有键,是一个可迭代对象,用 list转换为列表,用tuplel转为元组
d.values() :返回字典的所有值
d.items() :返回字典的所有项,键值对
# 5、字典推导式
l1=['张三','李四','周立'];
l2=[100,90,85];
d={x:y for x,y in zip(l1,l2)};
print(d);
2
3
4
# 12、集合set
python 中的集合对象是一组无序排列的可哈希的值,主要用于元素去重和关系测试。 集合成员可以做字典中的键。集合支持用 in 和 not in 操作符检查成员,集合本身是无序的,不可以为集合创建索引或执行切片操作,也没有键可用来获取集合中的值。
- 集合具有去重功能 ; 顺序不定
- 集合内的元素不可变,只能是数字、字符串、元组、字典、不可变集合等,不能是列表
s1= {1,2,4,5,6} # 集合 {a,b,c...} 不重复
l = [2,35,2,5,6]; #列表 [a,b,c...] 有顺序,可重复,可修改
t = (2,35,2,5,6); #元组 (a,b,c...) 有顺序,可重复,不可修改
d = {"name":'jim',"age":34}; # 字典 {key:value,k2:v2}
print(type(set));
print(type({})); # 新建空集合,不能用{}, 这里的类型为dict
print(set(l));
print(set(d)); # 将字典的key转成集合
2
3
4
5
6
7
8
9
# 集合创建
# 可变集合(set)
- 想要创建空集合,必须使用set()而不是{}。后者用于创建空字典。
# 不可变集合(frozenset)
# 集合的添加与删除

| 方法 | 描述 |
|---|---|
| add() (opens new window) | 向集合添加元素。 |
| clear() (opens new window) | 删除集合中的所有元素。 |
| copy() (opens new window) | 返回集合的副本。 |
| difference() (opens new window) | 返回包含两个或更多集合之间差异的集合。 |
| difference_update() (opens new window) | 删除此集合中也包含在另一个指定集合中的项目。 |
| discard() (opens new window) | 删除指定项目。 |
| intersection() (opens new window) | 返回为两个其他集合的交集的集合。 |
| intersection_update() (opens new window) | 删除此集合中不存在于其他指定集合中的项目。 |
| isdisjoint() (opens new window) | 返回两个集合是否有交集, 有交集返回False,无交集返回True |
| issubset() (opens new window) | 返回另一个集合是否包含此集合。 |
| issuperset() (opens new window) | 返回此集合是否包含另一个集合。 |
| pop() (opens new window) | 从集合中删除一个元素。 |
| remove() (opens new window) | 删除指定元素。 |
| symmetric_difference() (opens new window) | 返回具有两组集合的对称差集的集合。 |
| symmetric_difference_update() (opens new window) | 插入此集合和另一个集合的对称差集。 |
| union() (opens new window) | 返回包含集合并集的集合。 |
| update() (opens new window) | 用此集合和其他集合的并集来更新集合。 |
某元素是否在set里面 if item in s:
# 集合的循环和推导
集合推导式跟列表推导式差不多,都是对一个列表的元素全部执行相同的操作,但集合是一种无重复无序的序列
集合的特性是: 1.使用大括号{}; 2.结果中无重复; 3.结果是一个 set()集合,集合里面是一个序列。
import xlrd,xlwt
wb=xlrd.open_workbook('业绩达标表.xls');ws=wb.sheet_by_name('业绩')
nwb=xlwt.Workbook(encoding='uft-8');nws=nwb.add_sheet('结果')
col1=ws.col_values(0)[1:] # 从第二行开始 第一列的值 员工
col2=ws.col_values(1)[1:] # 月份
s=set(zip(col1,col2)) # zip压缩成元组,放在集合里面
s1={'%d月'%m for m in range(1,13)} #生成月份的集合
s2=set(col1) #员工的集合
r=0
for m in s2: #遍历员工集合
s3='/'.join(s1-{y for x,y in s if m==x}) #推导
nws.write(r,0,m);nws.write(r,1,s3)
r+=1
nwb.save('统计结果.xls')
2
3
4
5
6
7
8
9
10
11
12
13
14
# 集合关系
| 关系符号 | 描述 | |
|---|---|---|
| - | difference 差集、 sysmmetric.difference(对称差集) | 返回a集合中元素在b集合没有的 |
| & | intersection交集 | 返回交集,即两个集合中一样的元素 |
| | | union 合集、并集 | 返回合集,即合并去重 |
| != | 不等于 | 判断是否不相等 |
| == | 等于 | 判断是否相等 |
# 13、生成器generator
# 1.生成器
生成器(generator)也是一种迭代器,在每次迭代时返回一个值,直到抛出StopIteration异常。它有两种构造方式:
# (1)生成器表达式
和列表推导式的定义类似,生成器表达式使用 () 而不是 []
n = (i for i in range(5));
k = [i for i in range(5)];
print(n); # 生成器对象,不是元组 <generator object <genexpr> at 0x000001B1BF5A68E0>
print(k); # 列表 [0, 1, 2, 3, 4]
print(next(n)) # 0
2
3
4
5
6
# (2)生成器函数
含有yield关键字的函数,调用该函数时会返回一个生成器。
当我们使用 yield 时,它帮我们自动创建了__iter__() 和 next() 方法,而且在没有数据时,也会抛出 StopIteration 异常,也就是我们不费吹灰之力就获得了一个迭代器,非常简洁和高效。
带有 yield 的函数执行过程比较特别:
调用该函数的时候不会立即执行代码,而是返回了一个生成器对象;
- 当使用 next() (在 for 循环中会自动调用 next() ) 作用于返回的生成器对象时,函数 开始执行,在遇到 yield 的时候会『暂停』,并返回当前的迭代值;
- 当再次使用 next() 的时候,函数会从原来『暂停』的地方继续执行,直到遇到 yield语 句,如果没有 yield 语句,则抛出异常;
- 整个过程看起来就是不断地 执行->中断->执行->中断 的过程。一开始,调用生成器函数的时候,函数不会立即执行,而是返回一个生成器对象;然后,当我们使用 next() 作用于它的时候,它开始执行,遇到 yield 语句的时候,执行被中断,并返回当前的迭代值,要注意的是,此刻会记住中断的位置和所有的变量值,也就是执行时的上下文环境被保留起来;当再次使用 next() 的时候,从原来中断的地方继续执行,直至遇到 yield ,如果没有 yield ,则抛出异常。简而言之,就是 next 使函数执行, yield 使函数暂停。
普通函数调用,函数会立即执行直到执行完毕。 生成器函数调用,并不会立即执行函数体,而是返回一个生成器对象,需要使用next函数来驱动这个生成器对象,或者使用循环来驱动。 生成器表达式和生成器函数都可以得到生成器对象,只不过生成器函数可以写更加复杂的逻辑.
def func(): #只要有yield都算生成器函数,每一次生成器函数调用都会产生一个全新的生成器对象
for i in range(5):
print(i);
yield i; #遇到yield后,把yield后面的值返回出去,同时暂停当前函数执行
print(func()); # 生成器对象 <generator object func at 0x0000025B875865A0>
v = func();
print(next(v)); # 0 0 函数内打印0, 返值值为0,外面的print打印
print(next(v)); # 1 1
2
3
4
5
6
7
8
9
def func2():
print(1)
yield 2;
print(3)
yield 4;
return 5;
yield 6; #函数已返回,这句不起作用
r = func2();
next(r); # 打印1, 返回2
next(r); # 打印3, 返回4
next(r); # 返回5, StopIteration报错,因为next后面没有yield东西了
2
3
4
5
6
7
8
9
10
11
12
# 2.进阶使用
我们除了能对生成器进行迭代使它返回值外,还能:
使用 send() 方法给它发送消息; send()作为生成器对象的实例方法,可以向生成器发送数据并唤醒生成器函数。一般send()方法要写在next()方法后面,当next()和send()写在一块时,相当于唤醒两次生成器
使用 throw() 方法给它发送异常;
使用 close() 方法关闭生成器;
# 无限循环和计数器
def counter():
def inner():
i=0;
while True:
i+=1;
response = yield i; # send()时,response可以接收到参数值
if response is not None:
i=response;
c = inner(); # 生成器对象
def fn(start=0):
return c.send(start) if start >0 else next(c); # 有闭包
#return lambda: next(c); # 匿名函数,这里c是闭包
return fn;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 3、生成器应用
# 无限循环或计数器
# 无限循环
def counter():
def inner():
i=0;
while True:
i+=1;
yield i;
c = inner(); # 生成器对象
# def fn():
# return next(c); # 有闭包
return lambda: next(c); # 匿名函数,这里c是闭包
c = counter();
print(c());
2
3
4
5
6
7
8
9
10
11
12
13
14
# 斐波拉契序列
斐波拉契序列:第0项是0,第1项是第一个1。从第三项开始,每一项都等于前两项之和, 如 0, 1, 1, 2, 3, 5, 8, 13
# 斐波拉契序列: 第0项是0,第1项是第一个1。从第三项开始,每一项都等于前两项之和, 如 0, 1, 1, 2, 3, 5, 8, 13
def fib():
a = 0; # a代表前数
b=1; # b代表后数
yield b;
while True:
#temp = a + b; # 结果为前数+后数
#a= b; # 位置变换, 前数指向之前的后数
#b = temp # 后数为计算后的结果
a, b = b, a+b;
yield b;
f= fib();
for i in range(10):
print( next(f), end=" ");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 协和Coroutine
- 生成器的高级用法
- 它比进程、线程轻量级,是在用户空间调度函数的一种实现
- Python3 asyncio就是协程实现,已经加入到标准库 Python3.5 使用async、 await关键字直接原生支持协程
- 协程调度器实现思路 有2个生成器A、B,next(A)后,A执行到了yield语句暂停,然后去执行next(B),B执行到yield语句也暂停,然后再次调用next(A),再调用next(B)在,周而复始,就实现了调度的效果可以引入调度的策略来实现切换的方式
- 协程是一种非抢占式调度
我亲身感受,晚上我让孩子读书, 如果我在旁边玩手机或走开做自己的事,孩子的读书效果要差很多,很难坚持半小时, 而我在旁边陪着孩子读书或看自己的书,孩子要专心很多,甚至忘记时间
参考文章:
# 4、yield from
yield from 是yield的升级改进版本,如果将yield理解成“返回”,那么yield from就是“从什么(生成器)里面返回”,这就构成了yield from的一般语法,即
yield from generator yield from generator 实际上就是**返回另外一个生成器。**而yield只是返回一个元素。从这个层面来说,有下面的等价关系:yield from iterable本质上等于 for item in iterable: yield item 。
深入理解yield from语法 (opens new window)
# 14、 组包和拆包
组包: 将多个值同时赋给一个变量时,解释器会进行自动组包操作 拆包: 将一个容器值(元组),里面的多个数据同时赋值多个变量,解释器会进行拆包操作 注意: 拆包要注意被赋值的变量个数和元组中的值个数相同
# 15.相关函数和库
# enumerate
enumerate()是python的内置函数、适用于python2.x和python3.x enumerate在字典上是枚举、列举的意思,enumerate参数为可遍历/可迭代的对象(如列表、字符串) enumerate多用于在for循环中得到计数,利用它可以同时获得索引和值,即需要index和value值的时候可以使用enumerate, 索引从0开始,也可以指定开始位置 enumerate()返回的是一个enumerate对象
s = [1, 2, 3, 4, 5]
e = enumerate(s)
for index, value in e:
print('%s, %s' % (index, value))
2
3
4
# zip
Python 的 zip() 函数定义为 zip(*iterables)。该函数将可迭代对象作为参数并返回一个迭代器。此迭代器生成一系列元组,其中包含来自每个可迭代对象的元素。 zip() 可以接受任何类型的可迭代对象,例如文件、列表、元组、字典、集合等。
>>> numbers = [1, 2, 3]
>>> letters = ['a', 'b', 'c']
>>> zipped = zip(numbers, letters)
>>> zipped # Holds an iterator object
<zip object at 0x7fa4831153c8>
>>> type(zipped)
<class 'zip'>
>>> list(zipped)
[(1, 'a'), (2, 'b'), (3, 'c')]
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]
>>> numbers, letters = zip(*pairs) #解构
>>> numbers
(1, 2, 3, 4)
>>> letters
('a', 'b', 'c', 'd')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
参考: 彻底搞懂Python中的zip() (opens new window)
# 四、模块、包、库
Module(模块):扩展名为.py的文件就可以称做为模块,用来存放变量,方法的文件,便于在其他python文件中导入(通过import或from)。
Package(包):在模块之上的概念,为了方便管理.py 模块文件进行打包。包目录下第一个文件必须是__init__.py,否则就是普通的文件夹目录,然后是一些模块文件和子目录,假如子目录中也有__init__.py,那么它就是这个包的子包了。
Library(库):具有相关功能模块的集合。这也是 Python 的一大特色之一,即具有强大的标准库、第三方库以及自定义模块。
标准库,就是安装 Python 时自带的模块。
第三方库,就是由第三方机构发布的,具有特定功能的模块。用户也可以自行开发模块来供自己和他人使用。

# 安装与使用

1、导入模块方式一: import xlrd as xl, 后续就可以直接使用 xl 来代表 xlrd 模块。
2、方式二:from 模块名 import 方法名1,方法名2
比如导入 xlrd 模块中的 open_workbook,写法为:from xlrd import open_workbook,也可以使用别名命名方式,如:from xlrd import open_workbook as owb,后续就可以直接使用 owb 来代表 open_workbook 工作簿对象了
# from import用法
# 1、import使用方法
import 模块 [as 别名模块]
import 包.[n包].模块;
注:import 导入 最后一个必须是模块,而不能以包结尾
# 2、from使用方法:
from 包.[..包] import 模块
from 包.模块 import 方法
from 模块 import 方法。
注:from 包 import时,受__init__.py中的__all__影响,没有列出来的模块是没法导入引用的。
Python的from和import用法 - keena_jiao - 博客园 (cnblogs.com) (opens new window)
# Excel相关库
python -m pip install --upgrade pip #更新pip版本
pip install xlrd xlwt xlutils
pip uninstall xlrd
pip install xlrd==1.2.0
2
3
4
xlrd 只能读取 xls 格式工作簿数据, xlrd1.2.0之后的版本不支持xlsx格式,支持xls格式
xlwt 库,这个库才具有创建工作簿、工作表,将数据写入到单元格的功能
xlutils作为两个库的桥梁, 保存的工作簿可以和打开时的工作簿名一样,也可以不一样,如果一样,则是覆盖原工作簿,不一样则是另存工作簿;在运行代码时,被修改的工作簿必须关闭
os模块的作用主要是获取excel文件的路径
import os; # os模块的作用主要是获取excel文件的路径
import xlrd;
import xlwt;
from xlutils.copy import copy;
path = os.path.join(os.getcwd(), 'test.xlsx') # test.xlsx为py文件同目录下的文件,os.getcwd()为当前文件所在的目录
print(path);
#workbook = xlrd.open_workbook(path);
workbook = xlrd.open_workbook(r"D:\pycharmWorkspace\PycharmProjects\itheiMa\excel表格处理\test.xlsx");
# 获取所有的sheet
print("所有的工作表:",workbook.sheet_names());
# 根据sheet索引或者名称获取sheet内容
sheet1 = workbook.sheet_by_name('Sheet1')
sheet1 = workbook.sheet_by_index(0);
# 格式化输出sheet1的名称、行数、列数
print("工作表名称:%s,行数:%d,列数:%d" % (sheet1.name, sheet1.nrows, sheet1.ncols))
# 获取单元格内容的数据类型
# 类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
print("第三行第二列的值:%s, 数据类型:%s" % (sheet1.cell(2,1).value,sheet1.cell(0,1).ctype))
writeWB = xlwt.Workbook(encoding="UTF-8");
writeSheet = writeWB.add_sheet("测试工作表",cell_overwrite_ok=True);
writeSheet.write(1,2,"我是中国人");
writeWB.save("demo2.xls");
nWorkbook = copy(workbook);
nWorkbook.add_sheet("新的");
nWorkbook.save("test.xlsx");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
python操作xls文件,读取、写入、调整_笨猪起飞的博客-CSDN博客_python xls (opens new window)
# numpy
pip install numpy pandas matplotlib scipy tushare
# Django
pip install Django
# 五、变量与函数
函数是 python 编程中的核心内容之一。函数的最大优点是: 增强代码的重用性和可读性 。函数的本质是内存地址,类型为function
# 函数执行与调用过程
函数调用必须等函数返回了才能执行下一步
# 非数字型变量特点
除数字型外,其它的都是非数字型变量,有以下特点:
- 都是一个 序列
sequence,也可以理解为 容器 - 取值
[] - 遍历
for in - 计算长度、最大/最小值、比较、删除
- 链接
+和 重复* - 切片
# 1、自定义函数
在 Python 中,函数有五大要点,分别是 def、函数名、函数体、参数、返回值,分别是括号(括号内为参数)和冒号(:)。
- def:函数的关键字,没它可不行。
- 函数名:函数的名称,根据函数名调用函数。
- 函数体:函数中进行一系列的具体操作。
- 参数:为函数体提供数据。
- 返回值:当函数执行完毕后,可以给调用者返回数据。 Return 编写要返回的值,也是函数结束的标志, return 的返回值个数无限制,即可以用逗号分隔开多个任意类型的值。
# 语法结构
def 函数名称(参数1,参数2=默认值):
函数体
return 返回值
函数在有返回值的情况下会根据实际情况进行返回,如果函数没有返回值则返回None
在定义函数时,如果暂时还没想法可以用pass进行跳过
函数可以返回多个值,即return后可以跟多个参数,但函数本身返回只有一个值,其值为元组
函数名称是指向函数对象的引用,当把一个函数名称赋值给一个变量就是给它起了一个别名
# 函数的参数分类
形式参数和实际参数
可变长度参数
*args接受实际参数传递参数的时候会转化为元组的形式**[kwargs接受实际参数传递参数的时候会转化为字典的形式
默认值参数:用于定义函数,为参数提供默认值,调用函数时可传可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
在python3.8之后函数参数中允许出现
/和*号,/用来指明某些函数形参必须使用位置参数而非关键字参数的形式,*出现在函数参数中第一种含义可以表示为可变参数,,一般写作*args;对于单独出现在参数中的*参数,则表示,*后面的参数必须为关键字参数**kwargs的形式如果你希望调用者使用函数时一定不能使用关键字参数传参,那么只需要把这些参数放在
/前即可;如果你希望调用者使用函数时一定要使用某些参数,且必须为关键字参数传参,那么只需要把这些参数放在*后面即可。
def f(a, b, /, c, *, d, e):
print(a, b, c, d, e)
# a,b不能以关键字形式传参;c可以为任意型python所支持的值,d,e只能以关键字参数传参
2
3
# 关键字参数
用于函数调用,通过“键-值”形式加以指定。可以让函数更加清晰、容易使用,同时参数的编写可以不按顺序
def mid(txt,start,le=1):
s=txt[start:start+le]
return s
s='Excel与Python'
print(mid(s,3,5))
print(mid(le=5,start=3,txt=s))
2
3
4
5
6
# 不定长参数
不定长参数分为两种,一种位置传参为:*args,向这种参数写入的值是存储在元组中的。另一种为关键字传参:**kwargs,向这种参数写入的值是存储在字典中的
- 函数接收参数时,需要进行解构 fn(*args)
def add(x,y):
return x+y;
def logger(fn,*args, **kwargs):
print("{}函数,参数 {} {}".format(fn.__name__, args, kwargs)); #() {}
result = fn(*args, **kwargs);
print( result);
print("运行后日志");
logger(add, 12,23);
2
3
4
5
6
7
8
9
10
# 2、匿名函数lambda写法
没有名字的函数,不用写 return,返回值就是该表达式的结果。
- 程序一次性使用,所以不需要定义函数名,节省内存中变量定义空间
- 如果想让程序更加简洁时
lambda 参数 :函数体方法(或三元运算)
s = lambda a, b: a+b
print(s(1,2))
等价于
def func(a, b):
return a+b
2
3
4
5
6
7
- 由于lambda返回的是函数对象,因此我们需要用一个变量去接收
python 自定义函数_叁木-Neil的博客-CSDN博客_python 自定义函数 (opens new window)
# 3、高阶函数
# 函数是一等公民
标识符, 函数名(.__name__)
- 函数在Python是一等公民 (First-Class Object)函数也是对象,是可调用对象
- 函数可以作为普通变量,也可以作为函数的参数、返回值
只要满足下面的任意一个条件就是高阶函数
- 1、接收一个或多个函数作为参数
- 2、返回值(return)为一个
函数(返回为自己,则为递归)
# map
map函数接收的是两个参数,一个是函数名,另外一个是序列,其功能是将序列中的数值作为函数的参数依次传入到函数值中执行,然后再返回到列表中。返回值是一个迭代器对象
# filter
filter函数也是接收一个函数和一个序列的高阶函数,其主要功能是过滤。其返回值也是迭代器对象
# reduce
reduce函数也是一个参数为函数,另一个参数为可迭代对象 Iterable Object(eg: list列表)。,其返回值为一个值而不是迭代器对象,故其常用与叠加、叠乘等
# sorted
sorted()函数是一个高阶函数,它可以接收一个key函数来实现自定义的排序
sorted([36, 5, -12, 9, -21], key=abs, reverse=True) # 其它 key=str.lower
"""
高阶函数:参数或者返回值需为函数,有map reduce sorted filter
https://blog.csdn.net/weixin_41010198/article/details/103299135
"""
result = sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
print(result, type(result))
def f(x):
return x*2;
m = map(f, [1,2,3]); #返回的是一个迭代器对象
print( list(m), type(m) ) # 通过 list(map()) 将map函数返回的迭代对象转化为列表
from functools import reduce
def re(x,y):
# 放入reduce的函数,需要接收两个参数 ,执行时把前一个结果继续和序列的下一个元素做累积计算,其效果就是:reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
return x*10 + y
result = reduce(re, [1,2,3,6]);
print(result, type(result))
names=["Alex","amanda","xiaowu"]
result = filter(lambda x:x.islower(), names); # filter过滤,接收的函数的返回值需要为boolen类型
print( list(result), type(result)); # 迭代器类型
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
参考: python中的高阶函数 (opens new window)
# 4、内置函数
# type()
获取变量的类型, 在注解时,带上变量类型,在pycharm里面可以更友好代码提示
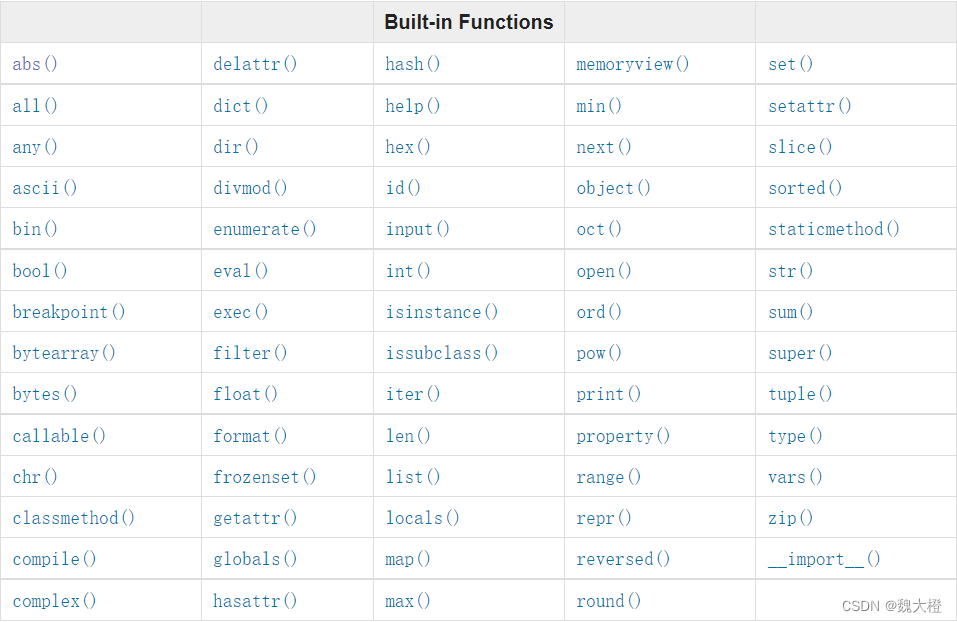
| abs() (opens new window) | 返回数的绝对值 |
|---|---|
| enumerate() (opens new window) | 获取集合(例如元组)并将其作为枚举对象返回。 |
| eval() (opens new window) | 评估并执行表达式。 |
| exec() (opens new window) | 执行指定的代码(或对象)。 |
| filter() (opens new window)、sorted() (opens new window)、map() (opens new window) | 使用过滤器函数排除可迭代对象中的项目。 |
| isinstance() (opens new window) | 如果指定的对象是指定对象的实例,则返回 True。 isinstance(True, int) 布尔是int的子类 |
| issubclass() (opens new window) | 如果指定的类是指定对象的子类,则返回 True。 |
| tuple() (opens new window)、set() (opens new window)、list() (opens new window)、dict() (opens new window) | 返回元组 集合 列表 字典。 |
参考: Python 内建函数 (opens new window)
# open()函数
要想读取文件(如txt、 csv等),第一步要用open()内建函数打开文件,它会返回一个文件对象,这个对象拥有read()、 write()、 close()等方法。
语法: file=open(path,mode='r',buffering=-1,encoding=None)
• file:打开的文件路径
• mode(可选):打开文件的模式,如只读、追加、写入等
• r:只读
• w:只写
• a:在原有内容的基础上追加内容(末尾)
• w+:读写
如果需要以字节(二进制)形式读取文件,只需要在mode值追加‘b’即可,例如wb
| 方法 | 描述 |
|---|---|
| f.read([size]) | 读取size字节,当未指定或给负值时,读取剩余所有的字节,作为字符串返回 |
| f.readline([size]) | 从文件中读取下一行,作为字符串返回。如果指定size则返回size字节 |
| f.readlines([size]) | 读取size字节,当未指定或给负值时,读取剩余所有的字节,作为列表返回 |
| f.write(str) f.flush | 写字符串到文件 刷新缓冲区到磁盘 |
| f.seek(offset[, whence=0]) | 在文件中移动指针,从whence(0代表文件起始位置,默认。 1代表当前位置。 2代表文件末尾)偏移offset个字节 |
| f.tell() | 当前文件中的位置(指针) |
| f.close() | 关闭文件 |
with语句: 不管在处理文件过程中是否发生异常,都能保证 with 语句执行完毕后已经关闭了打开的文件句柄。
with … as表达式 在写入文件时,如果忘了close或者flush,那么可能还有一些数据留在内存中,从而导致我们得到的文件是残缺的。
with as表达式可以通过调用对象中的__enter__方法和__exit__方法,来更加智能地调用close,从而免除了忘写close的麻烦。其调用方法为
with open('text.txt','w') as f:
f.write("12345")
2
python中的open用法详解_微小冷的博客-CSDN博客_python open (opens new window)
Python 基础 · 语雀 (yuque.com) (opens new window)
Python 教程 — Python 3.10.7 文档 (opens new window)
# 5、函数作用域与闭包
# 什么是作用域global
作用域就是指命名空间,python创建、改变或查找变量名都是在所谓的命名空间中。变量在赋值创建时,python中代码赋值的地方决定了这个变量存在于哪个命名空间,也就是它的可见范围。在Python中,只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如if、try、for等)是不会引入新的作用域的。
python中作用域 1.局部作用域,在函数内部或lambda、类中的全局局部变量中,调用函数时才会创建。每次调用都会创建一个新的本地作用域。调用结束后会销毁。(函数的参数也位于此作用域,这也解释了为什么不同函数,内部变量或参数名相同,并不引发冲突)。不可修改闭包作用域定义的变量,除非使用nonlocal语句。
2.闭包作用域(nonlocal),存在嵌套函数中,为其外层作用域。调用函数之后创建的变量不在此作用域。
3.全局作用域,顶层模块中所有函数外创建的全局变量。在函数内不可被修改,除非使用global语句,使用这些语句,也能在局部作用域创建全局变量。不过最好避免这种做法
4.内置作用域,builtins包,由python自动导入,一般为内置函数。如果担心其中命名被全局作用域覆盖,可显式写出。
与global不同,不能在嵌套或封闭函数之外使用nonlocal,也不能用nonlocal来创建变量。
x = 100; # 默认为全局变量
def f():
x+= 2; # 这里的x为本地变量,拿不到cannot access local variable 'x' where it is not associated with a value
return x;
def f2():
global x; # x标识符被global修饰,不再为本地变量,为全局变量,与本地作用域无关
x+= 2; # 这里的x为本地变量,拿不到cannot access local variable 'x' where it is not associated with a value
return x;
print(x); # 100
print(f2()); # 102
print(x); # 102
2
3
4
5
6
7
8
9
10
11
12
13
14
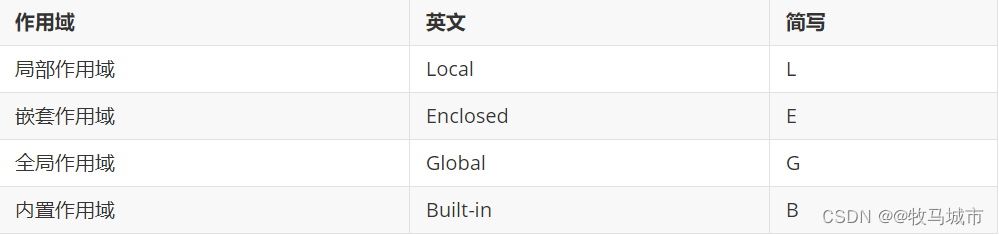
# 作用域的类型
Python变量作用域可以分为四种,分别为局部作用域、嵌套作用域、全局作用域、内置作用域;四种作用域中变量的调用顺序采取“就近原则”,即 LEGB法则。
定义:闭包就是外部函数中定义一个内部函数,内部函数引用外部函数中的变量,外部函数的返回值是内部函数;
# 闭包和nonlocal
自由变量: 未在本地作用域中定义的变量。例如定义在内层函数外的外层函数的作用域中的变量
闭包: 就是一个概念,出现在嵌套函数中,指的是内层函数引用到了外层函数的自由变量,就形成了闭包。很多语言都有这个概念,最熟悉就是]avaScript
闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境) 在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures), 是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。 所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。
- 作用1:闭包是将外层函数内的局部变量和外层函数的外部连接起来的一座桥梁。(下一部分讲解)
- 作用2:将外层函数的变量持久地保存在内存中。
nonlocal声明的变量不是局部变量,也不是全局变量,而是外部嵌套函数内的变量。
# 定义一个简单函数
def add(x,y): # add函数指向地址 addr1
return x+y
def logger(fn): # logger函数指向地址 addr2
# 定义内部函数,闭包
def wrapper(*args, **kwargs): # wrapper函数指向地址 addr3,但是函数体里面有调用fn,会开辟一个内存地址空间进行记录,若传入为add,则指向addr1
print("调用前");
result = fn(*args,**kwargs); #fn为原来的形参fn
print("调用后");
return result;
return wrapper; # 函数柯里化
add = logger(add); #右边优先执行,右边的add内存地址为addr1, 执行后,右边的add消亡,左边的add ==> wrapper,指向地址addr3, 闭包fn指向地址addr1
print(add(1,20)); # 这里的add是wrapper函数, 调用闭包fn执行
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17

局部变量无法共享和长久的保存,而全局变量可能造成变量污染,闭包既可以长久的保存变量又不会造成全局污染。
闭包使得函数内局部变量的值始终保持在内存中,不会在外层函数调用后被自动清除
闭包无法改变外部函数局部变量指向的内存地址, 形参就是局部变量
当外层函数返回了内层函数后,外层函数的局部变量还被内层函数引用
带参数的装饰器,那么一般都会生成闭包。
闭包在爬虫以及web应用中都有很广泛的应用。
def outer(): c=[0]; def inner(): c[0] += 1; print(c); return c; return inner foo = outer(); # outer运行后,c和inner消失,但其指向的地址未消亡。 foo指向 inner地址, c闭包,inner地址绑定c地址 foo(); # 值[1] c=[100] foo(); # 值[2]1
2
3
4
5
6
7
8
9
10
11
12

def f():
c=0;
def inner():
#global c; # 注意这里的全局变量global c和外面函数自由变量c不是同一个,想要为同一个的话,则改成nonlocal
nonlocal c; # non-local不是本地的, 朝外找最近的变量,但不能为全局变量
c += 1; # c=c+1 使用了c=,c就是局部变量,跟外面的c没有关系,所以没有闭包
print(c);
return c;
return inner
2
3
4
5
6
7
8
9
参考: https://zhuanlan.zhihu.com/p/453787908
Python中闭包详解及样例 (opens new window)
# 6、函数柯里化
柯里化 是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
fn(x, y) -> fn(x)(y)它的原理就是,把fn()函数做成嵌套函数,外层函数的返回值是内层函数,这样,外层函数调用完,返回的是一个函数,然后能接着调用。
"""
add(x,y,z) 转换为 add(x)(y)(z) 形式
即 add(x)(y) 为一个函数 => add(x)为函数
add2() 转换为 add2(x,y)(z) add2(x,y)为函数
"""
def add(x):
def addY(y):
def addZ(z):
return x+y+z;
return addZ;
return addY;
def add2(x,y):
def addZ(z):
return x+y+z;
return addZ;
result = add(5)(6)(9);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
https://blog.csdn.net/ivenqin/article/details/94380130
# 7、函数装饰器
Python提供一个更简洁引用装饰器的方法: 语法糖@标识符, 标识符指向一个函数(称为装饰器函数,wrapper),装饰下面的函数(称为被包装或被装饰函数 wrapped) ,无参装饰器logger,实际为单参函数, @logger会把下面紧挨 着的函数的标识符提上来作为它的实参
import datetime;
import time;
def copyProp(src):
def _copy(dest):
dest.__name__ = src.__name__
dest.__doc__ = src.__doc__
#其它的属性复制
return dest; #注意这里要返回目标函数
return _copy;
def logger(duration,output = lambda name, sec: print("{}函数,执行时间:{:.4f}秒".format(name, sec) )): # fn为被包装函数wrapped
def _log(fn):
@copyProp(fn) #带参装饰器,即 wrapper = copyProp(fn)(wrapper) => wrapper = _copy(wrapper) 在_copy函数里面需要返回值,不然wrapper为空
def wrapper(*args, **kwargs):
""" wrapper函数"""
oldTime = datetime.datetime.now();
print("{}函数,参数:{} {}".format(fn.__name__, args, kwargs));
result = fn(*args, **kwargs);
seconds = (datetime.datetime.now() - oldTime).total_seconds();
if seconds>duration:
output(fn.__name__, seconds);
#print(" 开始时间:{},运行了{:.4f}秒,{}".format( oldTime.time(), seconds, "Slow" if seconds>duration else "Fast" ) );
return result;
#copyProp(fn)(wrapper); #修改函数名和文档, 相当于@copyProp(fn)功能
return wrapper;
return _log;
@logger(3) # 相当于add = logger(3)(add) ==> add = wrapper
def add(x,y):
"""add函数"""
time.sleep(4) #休眠阻塞1秒
return x+y;
print(add(4,5));
print(add.__name__, add.__doc__); #wrapper wrapper函数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38

带参装饰器, 相当于先执行函数,再将下面的函数标识符作为参数传给执行后函数
@copyProp(fn) #带参装饰器,即 wrapper = copyProp(fn)(wrapper) def wrapper(*args, **kwargs):1
2
Python 函数装饰器 | 菜鸟教程 (runoob.com) (opens new window)
# 8、文档字符串
简称为 docstrings,在函数下方,添加注释,这个注释就是文档字符串,该文档字符串所约定的是一串多行字符串,其中第一行以某一大写字母开始,以句号结束。
第二行为空行,后跟的第三行开始是任何详细的解释说明。可以使用特殊属性__doc__获取
# -*- coding: UTF-8 -*-
# 文档字符串(Documentation Strings)
def print_max(x,y):
'''打印两个数值中的最大数。
这两个数都应该是整数'''
# 如果可能,将其转换至整数类型
x = int(x)
y = int(y)
if x>y:
print(x,'is maximum')
else:
print(y,'is maximum')
print_max(3,5)
print(print_max.__doc__)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 9、属性更新
上例中copy_properties是通用的功能,标准库 functools已经提供了, update_wrapper(函数版本) , wraps(偏函数实现,柯里化版本),解决文档、名称等问题
from functools import update_wrapper,wraps
def copy_properties(wrapper, wrapped): # 相当于update_wrapper,见其源码
wrapper.__name__ = wrapped.__name__;
wrapper.__doc__= wrapped.__doc__;
wrapper.__wrapped__=wrapped; #添加自定义属性,记录被装饰函数对象
return wrapper;
2
3
4
5
6
7
8
参考:
python中装饰器的使用教程详解(wraps) (opens new window)
# 10、注解annotation
# 01、函数注解
函数注解也是非强制性类型要求, pycharm工具会判断类型; 函数注解存放在函数属性__annotations__中,字典类型
def add(x:int, y:int)->int:
return x+y;
print(add.__annotations__); # {'x': <class 'int'>, 'y': <class 'int'>, 'return': <class 'int'>}
2
3
4
class Node:
def __init__(self):
self.val = None
self.left = None
def func(node: Node) # 直接写下类名,是Node类型
2
3
4
5
def func(x:int) -> float: # 表示输入类型为int,返回类型为float
return float(x**2)
def func2(f: callable[[int], float])
...
func2(func) # 调用
2
3
4
5
6
7
# 02、类型注解
非强制约束
# 03、类型检查
用装饰器+ __annotations__处理时,因为annotations是一个无序对象(python3.5以下),不大好判断参数。可以使用inspect库
import inspect;
from functools import wraps;
def check(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
#调用函数前进行参数检查
sig = inspect.signature(fn);
parameters = sig.parameters; #有序字典 OrdedDict
values = list(parameters.values());
#v.default, v.name, v.kind, v.annotation): <class 'inspect._empty'> x POSITIONAL_OR_KEYWORD <class 'int'>
for i,arg in enumerate(args):
if values[i].annotation is not values[i].empty and not isinstance(arg, values[i].annotation):
raise TypeError;
for k,v in enumerate(kwargs):
if values[k].annotation is not values[k].empty and not isinstance(v, values[i].annotation):
raise TypeError;
ret= fn(*args, **kwargs);
return ret;
return wrapper;
@check #add = check(add) => add=wrapper
def add(x:int, y:int)->int:
""" add 函数"""
if isinstance(x, int) and isinstance(y, int): #通用检查逻辑,硬编码,可以用装饰器来实现
return x+y;
else:
print("类型错误");
raise TypeError;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
inspect.signature(test)为提取test函数的签名;
inspect.signature(test).parameters为获取test的参数信息,为mappingproxy类型,它的值为为参数组成的一个OrderedDict,
inspect.Parameter对象的kind属性是一个_ParameterKind枚举类型的对象,一共有五种,POSITIONAL_ONLY、VAR_POSITIONAL、KEYWORD_ONLY、VAR_KEYWORD、POSITIONAL_OR_KEYWORD,分别代表着位置参数、可变参数、命名关键字参数、关键字参数,位置参数或命名关键字参数。
inspect.Parameter对象的default属性将返回参数的默认值,如果没有,返回一个inspect._empty类。
| 名称 | 含义 |
|---|---|
| POSITIONAL_ONLY | 只能作为位置参数 |
| POSITIONAL_OR_KEYWORD | 位置参数或关键字参数 |
| VAR_POSITIONAL | *args,传入后会以元组的形式展现 |
| KEYWORD_ONLY | 只能作为关键字参数 |
| VAR_KEYWORD | **kwargs,传入会以字典的形式展现 |
Python中inspect模块的一些认识 (opens new window)
# 六、循环语句与分支语句
# 1、for-in

for 循环语句除可以遍历指定范围的数字、字符串之外,还可以遍历列表、元素、集合、字典等对象
range() 函数语法为:
range(start, stop[, step]),参数说明如下:start:计数从 start 开始,包括start。默认是从 0 开始。stop:计数到 stop 结束,但不包括 stop。 [step]:步长,默认为 1
for n in "Shollin":
print("字符串:"+n,end="");
# 从0开始
for i in range(10):
print("数字:"+ str(i));
# 九九简法口诀
for row in range(1,10):
for col in range(1,row+1):
print("%d X %d = %d" % (col,row, row*col), end="\t"); #以制表符作为结束
print();
2
3
4
5
6
7
8
9
10
11
12
# 2、while
- while条件,小心产生死循环
- 死循环和input()、break结合,可以产生奇妙效果
i = 0;
url = "http://c.biancheng.net/python/"
while i<len(url):
print(url[i],end="");
i+=1;
row=1;
while row<=9:
col=1; #从1开始
while col<=row:
print("%d X %d = %d" % (col, row, row * col));
col+=1;
row+=1;
2
3
4
5
6
7
8
9
10
11
12
13
# 3、if-elif-else
while True:
age = int(input("请输入年龄:"));
if age>18:
print("已成年:" + str(age));
elif age>=7:
print("未成年,正是读书年纪" + str(age));
elif age >= 3:
print("幼儿园" + str(age));
else:
print("还没有上幼儿园:" + str(age));
break; #跳出循环
2
3
4
5
6
7
8
9
10
11
# 4、break/continue
break 语句可以立即终止当前循环的执行,跳出当前所在的循环结构。无论是 while 循环还是 for 循环,只要执行 break 语句,就会直接结束当前正在执行的循环体。这就好比在操场上跑步,原计划跑 10 圈,可是当跑到第 2 圈的时候,突然想起有急事要办,于是果断停止跑步并离开操场,这就相当于使用了 break 语句提前终止了循环。
continue只会终止执行本次循环中剩下的代码,直接从下一次循环继续执行。仍然以在操作跑步为例,原计划跑 10 圈,但当跑到 2 圈半的时候突然接到一个电话,此时停止了跑步,当挂断电话后,并没有继续跑剩下的半圈,而是直接从第 3 圈开始跑。
# 参考视频
No1058】从零基础入门到精通用Python处理Excel数据视频教程
网盘链接:https://pan.baidu.com/s/1BW7XDVoOjp3QQLhxz4sIRA
提取密码:7950 解压密码:www.javaxxz.com_(Ik&5D$HfQz
【No1685】python全栈自动化对标大厂视频课程
下载地址:
网盘链接:https://pan.baidu.com/s/1nxNPTrY1EhGeRRRt96jRjQ
提取密码:uisw
解压密码:www.javaxxz.com_)OI*unr5q
| 【No1792】马哥-2022年python全能工程师视频课程 | |
|---|---|
| 下载地址: | 网盘链接:https://pan.baidu.com/s/1tycd4U9D9Q47MuF3h-9H6g提取密码:5nl8解压密码:www.javaxxz.com_&H6bjm 注: |
文档:
Python 参考手册 (w3school.com.cn) (opens new window)
Python 标准库 — Python 3.10.2 文档 (yali.edu.cn) (opens new window)
# 七、面向对象
# 八、异常Exception
# 错误和异常
语法错误(syntax error)和异常(exception),错误是可以避免的,异常不可避免。
| 异常类型 | 含义 |
|---|---|
| AssertionError | 当 assert 关键字后的条件为假时,程序运行会停止并抛出 AssertionError 异常 |
| AttributeError | 当试图访问的对象属性不存在时抛出的异常 |
| IndexError | 索引超出序列范围会引发此异常 |
| KeyError | 字典中查找一个不存在的关键字时引发此异常 |
| NameError | 尝试访问一个未声明的变量时,引发此异常 |
| TypeError | 不同类型数据之间的无效操作 |
| ZeroDivisionError | 除法运算中除数为 0 引发此异常 |
| FileNotFundError |
# BaseException
BaseException 为所有异常的基类, 子类只需要覆盖父类的部分方法就可以了

# Exception
所有内建的、非系统退出的异常的基类, 自定义异常应该继承自它
# 异常捕获
# 捕获规则
- 捕获是从上到下依次比较,如果匹配,则执行匹配的except语句块
- 如果被一个except语句捕获,其他except语句就不会再次捕获了
- 如果没有任何一个except语句捕获到这个异常,则该异常向外抛出
- except: 称为缺省捕获,缺省捕获必须是最后一个捕获语句
捕获多个异常,会从上到下去匹配对应的异常,因此应该从小到大,从具体到宽泛
# as
# finally
无论try语句块里面是否有异常,finally都会执行
返回return的话,会压制异常,异常不会往外抛了
# else
try--except--else, try语句块里面没有任何异常发生时,执行else里面的语句, else不能单独出现,须与except搭配。
try:
<语句>#运行别的代码
except <异常类>:
<语句># 捕获某种类型的异常
except <异常类>as <变量名>: # 异常类由小到大
<语句> # 捕获某种类型的异常并获得对象
else:
<语句> #如果没有异常发生
finally:
<语句> #退出try时总会执行, return的话,会压制异常
2
3
4
5
6
7
8
9
10
1.如果try中语句执行时发生异常,搜索except子句,并执行第一个匹配该异常的except子句
2.如果try中语句执行时发生异常,却没有匹配的except子句,异常将被递交到外层的try,如果外层不处理这个异常,异常将继续向外层传递。如果都不处理该异常,则会传递到最外层,如果还没有处理,就终止异常所在的线程 3.如果在try执行时没有发生异常,如有else子句,可执行else子句中的语句
4.无论try中是否发生异常,finally子句最终都会执行