 python文件操作
python文件操作
# 文件操作
冯诺依曼体系架构
open 打开、read 读取、write 写入、close 关闭、readline 行读取、 readlines 多行读取、 seek 文件指针操作、 tell 指针位置
# 打开操作
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]])
- file:表示要创建的文件对象, 是一个可迭代对象
- file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
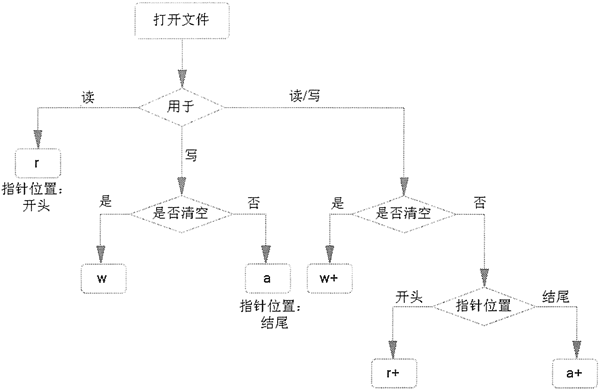
- mode:可选参数,用于指定文件的打开模式。可选的打开模式如表 1 所示。如果不写,则默认以只读(r)模式打开文件。rwxabt+ read/write/exists/append/binary/text/plus
- buffering:缓冲,可选参数,用于指定对文件做读写操作时,是否使用缓冲区。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 encoding 参数值也不同,以 Windows 为例,其默认为 cp936(codepage 936,实际上就是 GBK 编码),UTF-8编码

| 模式 | 意义 | 注意事项 |
|---|---|---|
| r | 只读模式打开文件,读文件内容的指针会放在文件的开头。 | 操作的文件必须存在。 |
| rb | 以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件等。 | |
| r+ | 打开文件后,既可以从头读取文件内容,也可以从开头向文件中写入新的内容,写入的新内容会覆盖文件中等长度的原有内容。 | |
| rb+ | 以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。 | |
| w | 以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| wb | 以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件) | |
| w+ | 打开文件后,会对原有内容进行清空,并对该文件有读写权限。 | |
| wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | |
| a | 以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 | |
| ab | 以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| a+ | 以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| ab+ | 以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |

参考:
手把手教你学Python之文件操作(一文掌握文件操作) (opens new window)
Python open()函数详解:打开指定文件 - C语言中文网 (opens new window)
# 上下文
ps aux | grep python
lsof | grep test | wc -l # lsof列出打开的文件,没有可以安装 yum install lsof
ulimit -a
2
3
4
上下文管理器(context manager),能够帮助你自动分配并且释放资源,其中最典型的应用便是with语句
f = open('test.txt', 'w')
try:
f.write('hello')
finally:
f.close() # 抛异常了也会执行此句
2
3
4
5
with 上下文对象 (as 别名):
with语句块结束了,自动调用该文件对象的close方法, 哪怕语句块里面出现异常。
with不会开辟作用域。
as子句后的标识符,指向with后的文件对象
参考:
python教程:上下文管理器详细教程 (opens new window)
# StringIO
StringIO 实际上是从内存当中读取字符串,然后放入缓冲区当中,缓冲区我们可以理解成一个类似于txt文件的一个容器,用来存放字符串,当字符串长度大的时候,使用SringIO能够提高效率
- 支持with上下文管理
- 一般来说,磁盘的操作比内存的操作要慢得多,内存足够的情况下,一般的优化思路是少落地,减少磁盘IO的过程,可以大大提高程序的运行效率
# StringIO 模块中的函数:
# s.read([n])
# 参数n限定读取长度,int类型;缺省状态为从当前读写位置读取对象s中存储的所有数据。读取结束后,读写位置被移动。
# s.readline([length])
# 参数length限定读取的结束位置,int类型,缺省状态为None:从当前读写位置读取至下一个以“\n”为结束符的当前行。读写位置被移动。
#
# s.readlines([sizehint])
# 参数sizehint为int类型,缺省状态为读取所有行并作为列表返回,除此之外从当前读写位置读取至下一个以“\n”为结束符的当前行。读写位置被移动。
# s.write(s)
# 从读写位置将参数s写入给对象s。参数s为str或unicode类型。读写位置被移动。
# s.writelines(list)
# 从读写位置将list写入给对象s。参数list为一个列表,列表的成员为str或unicode类型。读写位置被移动。
# s.getvalue()
# 此函数没有参数,返回对象s中的所有数据,无视指针,直接获取所有数据
# s.truncate([size])
# 从读写位置起切断数据,参数size限定裁剪长度,缺省值为None。
# s.tell()
# 返回当前读写位置。
# s.seek(pos[,mode])
# 移动当前读写位置至pos处,可选参数mode为0时将读写位置移动至pos处,为1时将读写位置从当前位置起向后移动pos个长度,
# 为2时将读写位置置于末尾处再向后移动pos个长度;默认为0。
# s.close()
# 释放缓冲区,执行此函数后,数据将被释放,也不可再进行操作。
# s.isatty()
# 此函数总是返回0。不论StringIO对象是否已被close()。
# s.flush()
# 刷新内部缓冲区
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# BytesIO
StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。
BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
# stdin、stdout、stderr
file-like对象
类文件对象,可以像文件对象一样操作
socket对象、输入输出对象(stdin、stdout)都是类文件对象
# 路径操作
# 路径操作模块
基名basename, 路径名dirname
__file__ : 返回当前文件的绝对路径
import os # 这里的os就是operation system的含义
# 获取当前运行文件所在的文件夹路径(当前的工作文件夹路径)
print(os.getcwd())#与.等价
print(os.path.abspath('.'))
# 获取当前运行文件路径
print(os.path.abspath('Test.py'))
# 获取当前文件所在文件夹的上级目录
print(os.path.abspath('..'))
2
3
4
5
6
7
8
9
10
from os import path
p = path.join('/a', 'b', 'c') #拼接,返回str
print(1, type(p), p)
print(2, path.exists(p))
print(3, path.split(p))
print(4, path.dirname(p), path.basename(p))
print(5, path.abspath(p))
print(6, path.abspath(''), path.abspath('.'))
print(7, path.splitdrive('c:/temp/test')) # windows method
print(8, path.splitdrive('/temp/test'))
# path.abspath() TypeError: abspath() missing 1 required positional argument: 'path'
print(__file__); # 返回当前文件的绝对路径,包含文件名 D:\pycharmWorkspace\PycharmProjects\马哥教育\文件操作\os的path.py
p = path.dirname(__file__); # 当前文件所在的目录
b = path.basename(__file__); # 当前文件的文件名,基名
print(b, p, path.dirname(p) ); # 返回文件所在目录或者上级目录
def getDrive(p): # 获取在哪一个盘符
while p != path.dirname(p):
p = path.dirname(p);
print(p);
return p;
getDrive(__file__); # D:\
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| 方法 | 解释 |
|---|---|
| path.join | 拼接一个路径出来 |
| path.exists | 判断该路径是否存在 |
| path.split | 将路径切割成头和尾的一个元组 |
| path.abspath | 返回一个绝对路径 |
| path.dirname | 返回文件所在‘目录’或上级目录 |
| path.basename | 返回路径的最后一部分 |
# pathlib模块Path类
/ 运算符重载 str / Path => Path, pathlib有两个主要的类,分别为PurePath和Path。

# 1)pathlib优势
相对于传统的os及os.path,pathlib具体如下优势:
- pathlib实现统一管理,解决了传统操作导入模块不统一问题;
- pathlib使得在不同操作系统之间切换非常简单;
- pathlib是面向对象的,路径处理更灵活方便,解决了传统路径和字符串并不等价的问题;
- pathlib简化了很多操作,简单易用。
# 2)pathlib和os常用操作对比
通过常用路径操作的对比,可以更深刻理解pathlib和os的区别,便于在实际操作中做对照,也便于进行使用替代,详细对比如下:
| pathlib操作 | os及os.path操作 | 功能描述 |
|---|---|---|
| Path.resolve() | os.path.abspath() | 获得绝对路径 |
| Path.chmod() | os.chmod() | 修改文件权限和时间戳 |
| Path.mkdir() | os.mkdir() | 创建目录 |
| Path.rename() | os.rename() | 文件或文件夹重命名,如果路径不同,会移动并重新命名 |
| Path.replace() | os.replace() | 文件或文件夹重命名,如果路径不同,会移动并重新命名,如果存在,则破坏现有目标。 |
| Path.rmdir() | os.rmdir() | 删除目录 |
| Path.unlink() | os.remove() | 删除一个文件 |
| Path.unlink() | os.unlink() | 删除一个文件 |
| Path.cwd() | os.getcwd() | 获得当前工作目录 |
| Path.exists() | os.path.exists() | 判断是否存在文件或目录name |
| Path.home() | os.path.expanduser() | 返回电脑的用户目录 |
| Path.is_dir() | os.path.isdir() | 检验给出的路径是一个文件 |
| Path.is_file() | os.path.isfile() | 检验给出的路径是一个目录 |
| Path.is_symlink() | os.path.islink() | 检验给出的路径是一个符号链接 |
| Path.stat() | os.stat() | 获得文件属性 |
| PurePath.is_absolute() | os.path.isabs() | 判断是否为绝对路径 |
| PurePath.joinpath() | os.path.join() | 连接目录与文件名或目录 |
| PurePath.name | os.path.basename() | 返回文件名,带后缀 |
| PurePath.parent | os.path.dirname() | 返回文件路径 |
| Path.samefile() | os.path.samefile() | 判断两个路径是否相同 |
| PurePath.suffix | os.path.splitext() | 分离文件名和扩展名 |
# 实际应用
# 获取文件列表
from pathlib import *
def file_list_handle(path, sub_dir=False, suffix_list=[]):
"""
path:输入路径,支持文件路径和文件夹路径
sub_dir:当为True时含子目录,为False时不含子目录
suffix_list:文件类型列表,按要求的列出全部符合条件的文件,为空时列出全部文件,如:[".xlsx",".xls"]
"""
file_list = []
if not suffix_list:
if sub_dir:
[suffix_list.append(Path(f).suffix) for f in Path(path).glob(f"**\*.*") if Path(f).is_file()]
else:
[suffix_list.append(Path(f).suffix) for f in Path(path).glob(f"*.*") if Path(f).is_file()]
suffix_list = list(set(suffix_list))
# [print(i) for i in suffix_list]
if Path(path).exists():
# 目标为文件夹
if Path(path).is_dir():
if sub_dir:
for i in suffix_list:
[file_list.append(str(f)) for f in Path(path).glob(f"**\*{i}")]
else:
[file_list.append(str(f)) for f in Path(path).iterdir() if Path(f).is_file and f.suffix in suffix_list]
elif Path(path).is_file():
file_list = [path]
# 去除临时文件
file_list_temp = []
for y in file_list:
if "~$" in Path(y).stem:
continue
file_list_temp.append(y)
file_list = file_list_temp
return file_list
else:
print("输入有误!")
return []
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# os模块
参考:
Python 路径操作 (opens new window)
# csv文件
# csv文件简介
逗号分隔值Comma-Separated Values。RFC 4180提出了MIME类型(”text/csv”)对于CSV格式的标准,可以作为一般使用的常用定义,满足大多数实现似乎遵循的格式。
CSV 是一个被行分隔符、列分隔符划分成行和列的文本文件。CSV 不指定字符编码
行分隔符为\r\n,最后一行可以没有换行符列分隔符常为逗号或者制表符。
每一行称为一条记录record
字段可以使用双引号括起来,也可以不使用。如果字段中出现了双引号、逗号、换行符必须使用双引号括起来。如果字段的值是双引号,使用两个双引号表示一个转义。
表头可选,和字段列对齐就行了
# 手动生成csv文件
# csv模块
Python中集成了专用于处理csv文件的库,名为:csv。
csv 库中有4个常用的对象:
- csv.reader :以列表的形式返回读取的数据; csv.reader(csvfile,dialect ='excel',** fmtparams)
- csv.writer :以列表的形式写入数据;
- csv.DictReader :以字典的形式返回读取的数据;
- csv.DictWriter:以字典的形式写入数据;
Python 使用csv库处理CSV文件 (opens new window)
# ini文件处理
.ini(即Initialization file),意为初始化文件,常常用于配置文件,包含环境参数、设定参数等等,它十分简洁,而且处理方便
ini文件有两个基本的组成部分,一是section(块),二是option(项),其中section由方括号和方括号中的名字组成,section的范围是当前方括号到下一个方括号的内容,section与section之间不能重名,区分大小写,option是section中的配置项,由key与value组成的键值对构成,一组key-value构成一个项,如key1 = value1(key与value之间用"="或者"😊;用" ; " 或者" # "表示注释,在ini文件中有一个特殊的section,[DEFAULT]必须大写,当其他section获取不到值时用该default下的option作为备用值。
读操作
读操作
read(filename) 读取文件内容(当配置文件有中文时,在调用read()方法时,需要传encoding="utf-8-sig"参数
sections() 获取所有的section,以列表形式返回,不包含缺省
options(section) 获取指定section的所有options,以列表形式返回,包含缺省
items(section) 获取指定section的所有键值对,以列表形式返回,包含缺省
get(section, option) 获取指定option的值,返回类型string, 会从缺省里面取, 若option和DEFAULT里面重复的话,会覆盖
写操作
write(fp) 将config对象写入ini文件
add_section(section) 添加一个新的section
set(section, option, value) 对指定section下的某个option赋值
remove_section(section) 删除某个section
remove_option(section, option) 删除某个section下的某个option
from configparser import ConfigParser
config:ConfigParser = ConfigParser();
s:list = config.read("test.ini", encoding="utf-8");
print(type(s),s);
for section in config.sections(): #返回所有的section,但不包含缺省
print(type(section), section);
print(config.options(section)); #每一个section下的options,包含缺省
print("-"*30);
for (k,v) in config.items(): # 所有的Section,包含缺省
print( type(k),k, type(v),v); # kv类型str, SectionProxy
print( config.items(k)); # 获取指定section的所有键值对,以列表形式返回,包含缺省
print("-" * 10);
s = config.get("s_no", "option"); # option和DEFAULT里面重复的话,会覆盖
s2 = config.get("s_no", "stu00");
print(s, s2);
config.add_section("test"); # 添加section, 可以用config[] 形式获取到
config["test"]["aa"]="1000"; # 赋值必须是字符串
with open("t.ini", mode="w") as f: # ini文件写入
config.write(f); #保存时,会去掉注释并格式化ini文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 注释需要单独占一行,默认section 必须是大写DEFAULT
[DEFAULT]
stu00 = 66
[s_name]
ini =
option = student_name
stu1 = xh
[s_no]
option = student_no
stu2 = 23
stu00 = 88
[s_title]
#kv键值对,可以是:或者=
option:123
stu3 : 33
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
参考:Python ini配置文件操作 (opens new window)
# 序列化和反序列化
# 为什么要序列化
内存中的字典、列表、集合以及各种对象,如何保存到一个文件中? 如果是自己定义的类的实例,如何保存到一个文件中? 如何从文件中读取数据,并让它们在内存中再次恢复成自己对应的类的实例? 要设计一套协议,按照某种规则,把内存中数据保存到文件中。文件是一个字节序列,所以必须把数据转换成字节序列,输出到文件。这就是序列化。反之,从文件的字节序列恢复到内存并且还是原来的类型,就是反序列化.
- serialization 序列化:要设计一套协议,按照某种规则,把内存中数据保存到文件中。文件是一个字节序列,所以必须把数据转换成字节序列,输出到文件。这就是序列化。
- deserialization 反序列化:反之,从文件的字节序列恢复到内存中并且还原原来的类型,就是反序列化。
- 序列化保存到文件就是持久化。可以将数据序列化后持久化,或者网络传输;也可以将从文件中或者网络接收到的字节序列反序列化。
# pickle库
pickle库是 Python 中的序列化/反序列化模块pickle库不推荐使用,序列化后所占空间比较大,不利于网络传输和硬盘存储,但是便于大家理解序列化和反序列化原理

pickle 模块实现了用于对 Python 对象结构进行序列化和反序列化的二进制协议,与 json 模块不同的是 pickle 模块序列化和反序列化的过程分别叫做 pickling 和 unpickling:
- pickling:是将 Python 对象转换为字节流的过程
- dumps(object):将 python 对象转换(序列化)为字节(二进制)对象。
- dump(object, file):将对象写到文件,这个文件可以是实际的物理文件,也可以是任何类似于文件的对象,这个对象具有 write() 方法,可以接受单个的字符串参数。
- unpickling: 是将字节流二进制文件或字节对象转换回 Python 对象的过程
- loads(string):将二进制对象转换(反序列为)为 python 对象。
- load(file):返回包含在 pickle 文件中的对象。
序列化类对象之后,反序列化的时候应该使用同样的类定义
# pickle模块与json模块对比:
JSON是一种文本序列化格式(它输出的是unicode文件,大多数时候会被编码为utf-8),而pickle是一个二进制序列化格式; JOSN是我们可以读懂的数据格式,而pickle是二进制格式,我们无法读懂; JSON是与特定的编程语言或系统无关的,且它在Python生态系统之外被广泛使用,而pickle使用的数据格式是特定于Python的; 默认情况下,JSON只能表示Python内建数据类型,对于自定义数据类型需要一些额外的工作来完成;pickle可以直接表示大量的Python数据类型,包括自定数据类型(其中,许多是通过巧妙地使用Python内省功能自动实现的;复杂的情况可以通过实现specific object API来解决)
import pickle
filename = "aa.bin";
i = 100;
s="aa";
l = list(range(1,5));
d = {"a":1,"b":"abc","c":[12,13]};
# 序列化
with open(filename, "wb") as f:
pickle.dump(i, f);
pickle.dump(s, f);
pickle.dump(l, f);
pickle.dump(d, f);
#反序列化
with open(filename, "rb") as f:
for l in range(4):
v = pickle.load(f)
print(v, type(v));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
参考:Python 中实现数据序列化 (opens new window)
# Json
JSON 时一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。
# json的数据类型
官网查看数据类型:JSON 数据类型 (opens new window)
- 值:双引号引起来的字符串,数值,
true和false,null, 对象,数组,这些都是值、 - 字符串:由双引号包围起来的任意字符的组合,可以有转义字符
- 数值:有正负/整数/浮点数
- 对象:无序的键值对的集合
- 数组:有序的值的集合
[value1, ..., valuen]
# json模块

| Python 类型 | Json 类型 |
|---|---|
| True | true |
| False | false |
| None | null |
| str | string |
| int | integer |
| float | float |
| lsit | array |
| dict | objext |
- 一般
Json编码的数据很少落地,数据都是通过网络传输的。传输的时候,要考虑进行压缩。 - 本质上说
Json就是个文本,就是个字符串 Json很简单,几乎编程语言都支持Json,所以应用范围十分广泛
# MessagePack
MessagePack 是一个基于二进制高效的对象序列化类库,可用于跨语言通信。它可以像JSON那样,在许多种语言之间交换结构对象。但是它比 JSON 更快速更轻巧。 MessagePack 简单易用,高效压缩,支持语言丰富。用它序列化也是一种很好的选择。 [MessagePack 官网](pip install msgpack)
pip install msgpack
- packb 序列化对象,提供了 dumps 来兼容 pickle 和 json
- unpackb 反序列化对象,提供了 loads 来兼容
- pack 序列化对象保存到文件对象。提供了 dump 来兼容
- unpack 反序列化对象保存到文件对象,提供了 load 来兼容
import msgpack
from io import BytesIO
buf = BytesIO()
for i in range(100):
buf.write(msgpack.packb(i, use_bin_type=True))
buf.seek(0)
unpacker = msgpack.Unpacker(buf, raw=False)
for unpacked in unpacker:
print(unpacked)
2
3
4
5
6
7
8
9
10
11
12
MessagePack简单易用,高效压缩,支持语言丰富。 所以,用它序列化也是一种很好的选择。Python很多大名鼎鼎的库都是用了msgpack。 上例中,之所以pickle比json序列化的结果还要大,原因主要是pickle要解决所有Python类型数据的序列化,要记录各种数据类型包括自定义的类。而Json只需要支持少数几种类型,所以就可以很简单,都不需要类型的描述字符。但大多数情况下,我们序列化的数据都是这些简单的类型。